
AI on premise: benefits and a predictive-modeling use case
by aymen frikha on 24 March 2021
Running an Artificial Intelligence (AI) infrastructure on premise has major challenges like high capex and requires internal expertise. It can provide a lot of benefits for organisations that want to establish an AI strategy. The solution outlined in this post illustrates the power and the utility of Juju, a charmed Operator Lifecycle Manager (OLM), to create and manage on premise AI infrastructure. This infrastructure is able to support the MLOps of a commonly used AI use case about Financial time series data and predictive modeling.
Benefits of an AI on premise solution
Any organisation seeking to establish an AI strategy should consider several key criteria. Economics is oftentimes one of the most important criteria when procuring and building AI technology and infrastructure. However, several other criteria – flexibility, usability and security – must also be taken into account to build an efficient short and long-term strategy.
When looking at the financial, operational and security criteria, one major decision to be made is whether to build and host the application on a public cloud or build an on-premise infrastructure. Considering the cost and the difficulty of managing specialized AI servers and the market trend to deploy new applications in the public cloud, deploying and building AI on-premise infrastructure offers significant benefits:
Building your own private cloud can reduce costs
Using public cloud services is tremendously sticky. If you use AWS services to develop a chatbot, for example, It would be very difficult to move this application from Amazon given the dependency with the APIs and public cloud services. This example can also be applied for Google and Microsoft public cloud services.
Being sticky to public cloud services is not necessarily a negative, as they offer a rich catalog of applications as well as out-of-the-box AI capabilities that can facilitate the implementation and the development of your AI workloads.
The main catch here is that when you progress on your AI journey, things can become very bad very quickly. AI development needs a lot of computational resources as well as long running training jobs (days to weeks) to be able to make your neural networks useful and up to date with fresh data and features. This level of compute can become expensive in the cloud, costing 2-3 times as much as building your own private cloud to train and run the neural networks.
On-premise inherits standard security processes
Many companies already have established security rules and defined processes that most likely will be broken if they choose to start their AI journey on the public cloud. Financial and government companies are good examples of how public clouds may not meet exact or unique security and compliance requirements that can be more easily implemented with an on premise solution. .
Costs and resources that come with Data Gravity
One of the biggest problems for companies that want to use public cloud services for AI is how to use the data they have been collecting for years. If your data is on premise, the hassle and costs of data transfers can be onerous, especially considering the massive size of neural network training datasets. For that reason, it usually makes sense to build your AI on-prem as well.
Financial time series predictive modeling use case: predicting whether the S&P 500 Index will close positive or negative
Canonical engineers use a proven and economical architecture to run this financial time series use case in an AI/ML infrastructure. The goal is to have an end-to-end on premise solution that can support the whole MLops workflow, from the model creation to production deployment.
The use case can be described as follows:
“ We use AI and deep neural networks to elaborate a model that will try to predict whether the S & P 500 market index will close positive or negative based on historical information from the stock markets.
Financial markets are increasingly global: you can use information from an earlier time zone to your advantage in a later time zone. ”
Rather than focusing on the source code of the use case, which is already covered in multiple blog posts and Kubeflow samples, in this blog post we want to make the emphasis on the on-prem environment architecture, workflow and components to run it.
To be able to construct the time series prediction model and make it available for financial market services we will realize several steps:
- Obtain data of a number of financial markets from a data store and munge it into a usable format.
- Use TensorFlow to build and train models for predicting whether the market index will close positive or negative.
- Send a trained model to an object store system.
- Serve the trained model using tensorflow serving into a distributed messaging bus.
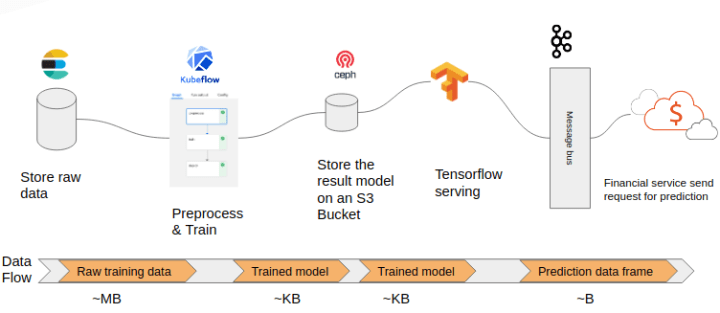
The workflow of our use case is illustrated in figure 1. We are using multiple open source components to achieve our goal. Indeed, We are using the charmed distribution of those applications to be able to take advantage of the power of OLM in the deployment and management life cycles.
Charms encapsulate a single application and all the code and know-how it takes to operate it, such us how to combine and work with other related applications or how to upgrade it. Charms are programmed to understand a single application, its operations, and its potential to communicate or integrate with other applications. A charm defines and enables the channels by which applications connect.
The following charms and set of charms has been used for this demonstration:
- Elasticsearch: Elasticsearch is a flexible and powerful open source, distributed, real-time search and analytics engine. Architected from the ground up for use in distributed environments where reliability and scalability are must haves, Elasticsearch gives you the ability to move easily beyond simple full-text search.
- Kubeflow Pipeline: Kubeflow Pipelines is a comprehensive solution for deploying and managing end-to-end ML workflows. Use Kubeflow Pipelines for rapid and reliable experimentation. You can schedule and compare runs, and examine detailed reports on each run.
Charmed Kubeflow lite Bundle ›
- Ceph: Ceph is a distributed storage and network file system designed to provide excellent performance, reliability and scalability. It can also be used as an object storage system and provide an S3 endpoint.
- Tensorflow serving: TensorFlow Serving is a flexible, high-performance serving system for machine learning models, designed for production environments. TensorFlow Serving makes it easy to deploy new algorithms and experiments, while keeping the same server architecture and APIs. TensorFlow Serving provides out-of-the-box integration with TensorFlow models, but can be easily extended to serve other types of models and data.
- This is the link for the charmed version: https://jaas.ai/u/kubeflow-charmers/tf-serving
- Kafka: Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration and mission-critical applications.
- This is the charmed version: https://jaas.ai/u/narindergupta/kafka

Basically, we start by running the Financial Time Series Kubeflow pipeline. First of all, in the preprocess step, we download raw data from elasticsearch and preprocess it. The data represents old closing values of multiple stock markets (aord, dax, djia, nyse, snp …). Then, in the train step, we train a neural network model with the preprocessed data. In this step, we use Tensorflow library to train the model and we are able to execute it using CPU or GPU. Finally, in the deploy step, we upload the result model into an s3 bucket inside Ceph.
The tensorflow server downloads the trained model from the ceph s3 bucket and serves it through Kafka.
Environment
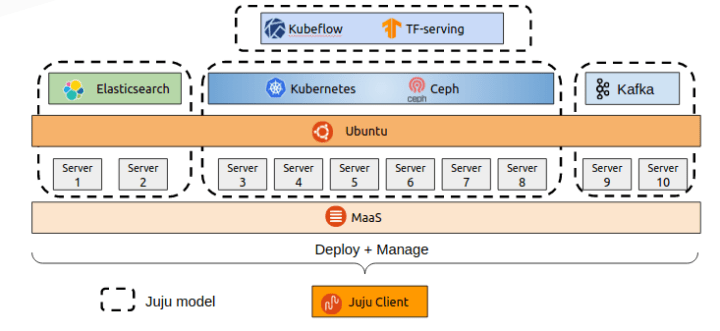
Figure 3 represents a high level view of our environment. What is inside the dashed box represents a Juju environment or a Juju model.
The elasticsearch, k8s and kafka services will be deployed and managed through Juju on top of VMs that are provisioned by MAAS. Kubeflow and tensorflow server services will be deployed on top of Kubernetes also through Juju.
Basically elasticsearch will be used to store the raw data that will be used to train our model.
K8s, will be used to run the Kubeflow platform and the tensorflow serving. Ceph will be used mainly as an object storage system to store our trained model. It also acts as a block storage system to store persistent volumes for our Kubernetes pods. Kafka actx as a messaging bus between the model server and the client applications.
As mentioned before all the components deployed in this environment are done through Juju and the charms. Figure 4 shows the environment result through Juju gui.

Conclusion
Join thousands of developers and enterprises that chose Ubuntu as their platform for development, innovation and production workloads.
Let’s take off together!
Related posts
Cut data center energy costs with bare metal automation
Data centers don’t have to be power-hungry monsters. With smart automation using tools like MAAS, you can reduce energy waste and operational costs, and make your infrastructure greener, without sacrificing performance or flexibility. […]
Effective infrastructure automation to reduce data center costs
To truly reduce OpEx, you must shift your perspective from seeing operations as custom, artisanal work to one where operations are standardized, automated, and repeatable. In other words, commoditized. […]
OpenStack with Sunbeam for medium-scale cloud infrastructure
The rapid growth in OpenStack installation and orchestration tools that we have seen in recent years has effectively established OpenStack as the world’s leading open source cloud platform. Projects like Sunbeam or Kolla Ansible, for example, are effectively transforming OpenStack into yet another user application. By using containers and […]